I recently ran into some internal buzz about Oracle’s 72 port ‘top-of-rack’ switch announcement and it peeked my interest, so I started taking a look. Oracle selling a switch is definitely interesting on the surface but then again they did just purchase Sun for a bargain basement price and Sun…
Month: July 2010
Data Center 101: Local Area Network Switching
Interestingly enough 2 years ago I couldn’t even begin to post an intelligent blog on Local Area Networking 101, funny how things change. That being said I make no guarantees that this post will be intelligent in any way. Without further ado let’s get into the second part of the…
How Emulex Broke Out of the ‘Card Pusher’ Box
A few years back when my primary responsibility was architecting server, blade, SAN, and virtualization solutions for customers I selected the appropriate HBA based on the following rule: Whichever (Qlogic or Emulex) is less expensive today through the server OEM I’m using. I had no technical or personal preference for…
FCoTR a Storage Revolution
As the industry has rapidly standardized and pushed adoption of Fibre Channel over Ethernet (FCoE) there continue to be many skeptics. Many Fibre Channel gurus balk at the idea of Ethernet being capable of guaranteeing the right level of lossless delivery and performance required for the SCSI data their disks…
Concepts
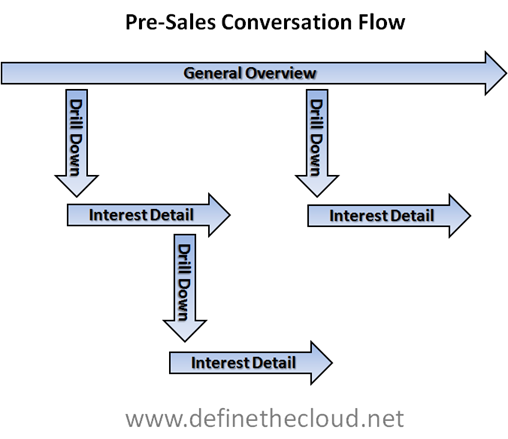
The Art of Pre-Sales
On a recent customer call being led by a vendor account manager and engineer I witnessed some key mistakes by the engineer as he presented the technology to the customer. None of the mistakes were glaring or show stopping but they definitely kept the conversation from having the value that…
Data Center 101: Server Systems
As the industry moves deeper and deeper into virtualization, automation, and cloud architectures it forces us as engineers to break free of our traditional silos. For years many of us were able to do quite well being experts in one discipline with little to no knowledge in another. Cloud computing,…
Have We Taken Data Redundancy too Far?
During a recent conversation about disk configuration and data redundancy on a storage array I began to think about everything we put into data redundancy. The question that came to mind is the title of this post ‘Have we taken data redundancy too far?’ Now don’t get me wrong, I…
Why Cloud is as ‘Green’ As It Gets
I stumbled across a document from Greenpeace citing cloud for additional power draws and the need for more renewable energy (http://www.greenpeace.org/international/en/publications/reports/make-it-green-cloud-computing/.) This is one of a series I’ve been noticing from the organization bastardizing IT for its effect on the environment and chastising companies for new data centers. These articles…