Note: I have made updates to reflect that Virtual Connect is two words, and technical changes to explain another method of network configuration within Virtual Connect that prevents the port blocking described below. Many thanks to the Ken Henault at HP who graciously walked me through the corrections, and beat them into my head until I understood them.
I’m sitting on a flight from Honolulu to Chicago in route home after a trip to Hawaii for customer briefings. I was hoping to be asleep at this point but a comment Ken Henault left on my ‘FlexFabric – Small Step, Right Direction’ post is keeping me awake… that’s actually a lie, I’m awake because I’m cramped into a coach seat for 8 hours while my fiancé, who joined me for a couple of days, enjoys the first class luxuries of my auto upgrade, all the comfort in the world wouldn’t make up for the looks I got when we landed if I was the one up front.
So, being that I’m awake anyway I thought I’d address the comment from the aforementioned post. Before I begin I want to clarify that my last post had nothing to do with UCS, I intentionally left UCS out because it was designed with FCoE in mind from the start so it has native advantages in an FCoE environment. Additionally within UCS you can’t get away from FCoE, if you want Fibre Channel connectivity your using FCoE so it’s not a choice to be made (iSCSI, NFS, and others are supported but to connect to FC devices or storage it’s FCoE.) The blog was intended to state exactly what it did: HP has made a real step into FCoE with FlexFabric but there is still a long way to go. To see the original post click the link (http://www.definethecloud.net/?p=419.)
I’ve got a great deal of respect for both Ken and HP whom he works for. Ken knows his stuff, our views may differ occasionally but he definitely gets the technology. The fact that Ken knows HP blades inside, outside, backwards forwards and has a strong grasp on Cisco’s UCS made his comment even more intriguing to me, because it highlights weak spots in the overall understanding of both UCS and server architecture/design as it pertains to network connectivity.Â
Scope:
This post will cover the networking comparison of HP C-Class using Virtual Connect (VC) modules and Virtual Connect (VC) management as it compares to the Cisco UCS Blade System. This comparison is the closest ‘apples-to-apples’ comparison that can be done between Cisco UCS and HP C-Class. Additionally I will be comparing the max blades in a single HP VC domain which is 64 (4 chassis x 16 blades) against 64 UCS blades which would require 8 Chassis.
Accuracy and Objectivity:
It is not my intent to use numbers favorable to one vendor or the other. I will be as technically accurate as possible throughout, I welcome all feedback, comments and corrections from both sides of the house.
HP Virtual Connect:
VC is an advanced management system for HP C-Class blades that allows 4 blade chassis to be interconnected and managed/networked as a single system. In order to provide this functionality the LAN/SAN switch modules used must be VC and the chassis must be interconnected by what HP calls a stacking-link. HP does not consider VC Ethernet modules to be switches, but for the purpose of this discussion they will be. I make this decision based on the fact that: They make switching decisions and they are the same hardware as the ProCurve line of blade switches.
Note: this is a networking discussion so while VC has other features they are not discussed here.
Let’s take a graphical view of a 4-chassis VC domain.
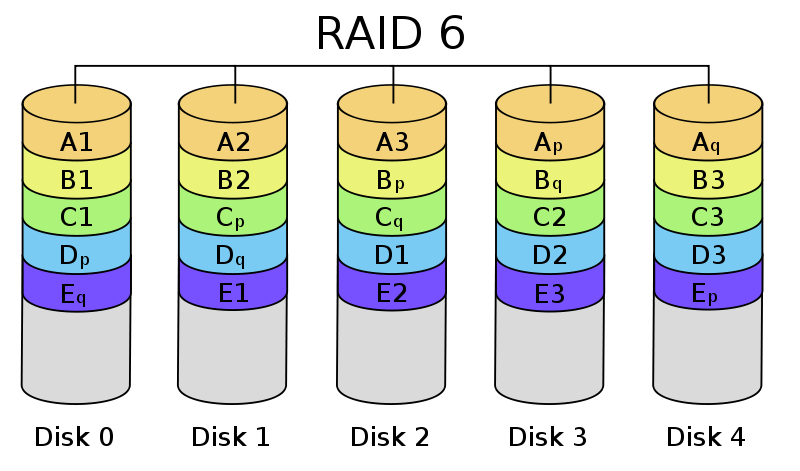
 In the above diagram we see a single VC domain cabled for LAN and SAN connectivity. You can see that each chassis is independently connected to SAN A and B for Fibre Channel access, but Ethernet traffic can traverse the stacking-links along with the domain management traffic. This allows a reduced number of uplinks to be used from the VC domain to the network for each 4 chassis VC domain. This solution utilizes 13 total links to provide 16 Gbps of FC per chassis (assuming 8GB uplinks) and 20 Gbps of Ethernet for the entire VC domain (with blocking considerations discussed below.) More links could be added to provide additional bandwidth.
In the above diagram we see a single VC domain cabled for LAN and SAN connectivity. You can see that each chassis is independently connected to SAN A and B for Fibre Channel access, but Ethernet traffic can traverse the stacking-links along with the domain management traffic. This allows a reduced number of uplinks to be used from the VC domain to the network for each 4 chassis VC domain. This solution utilizes 13 total links to provide 16 Gbps of FC per chassis (assuming 8GB uplinks) and 20 Gbps of Ethernet for the entire VC domain (with blocking considerations discussed below.) More links could be added to provide additional bandwidth.
This method of management and port reduction does not come without its drawbacks. In the next graphic I add loop prevention and server to server communication.

The first thing to note in the above diagram is the blocked link. When only a single vNet is configured accross the VC Domain (1-4 chassis) only 1 link or link aggregate group may forward per VLAN. This means that per VC domain there is only one ingress or egress point to the network per VLAN. This is because VC is not ‘stacking’ 4 switches into one distributed switch control plane but instead ‘daisy-chaining’ four independent switches together using an internal loop prevention mechanism. This means that to prevent loops from being caused within the VC domain only one link can be actively used for upstream connectivity per VLAN.
Because of this loop prevention system you will see multiple-hops for frames destined between servers in separate chassis, as well as frames destined upstream in the network. In the diagram I show a worst case scenario for educational purposes where a frame from a server in the lower chassis must hop three times before leaving the VC domain. Proper design and consideration would reduce these hops to two max per VC domain.
**Update**
This is only one of the methods available for configuring vNets within a VC domain. The second method will allow both uplinks to be configured using separate vNets which allows each uplink to be utilized even within the same VLANs but segregates that VLAN internally. The following diagram shows this configuration.

In this configuration server NIC pairs will be configured to each use one vNet and NIC teaming software will provide failover. Even though both vNets use the same VLAN the networks remain separate internally which prevents looping, upstream MAC address instability etc. For example a server utilizing only two onboard NICs would have one NIC in vNet1 and one in vNet2. In the event of an uplink failure for vNet1 the NIC in that vNet would have no north/south access but NIC teaming software could be relied upon to force traffic to the NIC in vNet 2.Â
While both methods have advantages and disadvantages this will typically be the preferred method to avoid link blocking and allow better bandwidth utilization. In this configuration the center two chassis will still require an extra one or two hops to send/receive north/south traffic depending on which vNet is being used.
**End Update**
The last thing to note is that any Ethernet cable reduction will also result in lower available bandwidth for upstream/northbound traffic to the network. For instance in the top example above only one link will be usable per VLAN. Assuming 10GE links, that leaves 10G bandwidth upstream for 64 servers. Whether that is acceptable or not depends on the particular I/O profile of the applications. Additional links may need to be added to provide adequate upstream bandwidth. That brings us to our next point:
Calculating bandwidth needs:
Before making a decision on bandwidth requirements it is important to note the actual characteristics of your applications. Some key metrics to help in design are:
- Peak Bandwidth
- Average Bandwidth
- East/West traffic
- North/South Traffic
For instance, using the example above, if all of my server traffic is East/West within a single chassis then the upstream link constraints mentioned are mute points. If the traffic must traverse multiple chassis the stacking-link must be considered. Lastly if traffic must also move between chassis as well as North/South to the network, uplink bandwidth becomes critical. With networks it is common to under-architect and over-engineer, meaning spend less time designing and throw more bandwidth at the problem, this does not provide the best results at the right cost.
Cisco Unified Computing System:
Cisco UCS takes a different approach to providing I/O to the blade chassis. Rather than placing managed switches in the chassis UCS uses a device called an I/O Module or Fabric Extender (IOM/FEX) which does not make switching decisions and instead passes traffic based on an internal pinning mechanism. All switching is handled by the upstream Fabric Interconnects (UCS 6120 or 6140.) Some will say the UCS Fabric Interconnect is ‘not-a-switch’ using the same logic as I did above for HP VC devices the Fabric Interconnect is definitely a switch. In both operational modes the interconnect will make forwarding decisions based on MAC address.
One major architectural difference between UCS and HP, Dell, IBM, Sun blade implementations is that the switching and management components are stripped from the individual chassis and handled in the middle of row by a redundant pair of devices (fabric interconnects.) These devices replace the LAN Access and SAN edge ports that other vendors Blade devices connect to. Another architectural difference is that the UCS system never blocks server links to prevent loops (all links are active from the chassis to the interconnects) and in the default mode, End Host mode it will not block any upstream links to the network core. For more detail on these features see my posts: Why UCS is my ‘A-Game Server Architecture http://www.definethecloud.net/?p=301, and UCS Server Failover http://www.definethecloud.net/?p=359.)Â
A single UCS implementation can scale to a max 40 Chassis 320 servers using a minimal bandwidth configuration, or 10 chassis 80 servers using max bandwidth depending on requirements. There is also flexibility to mix and match bandwidth needs between chassis etc. Current firmware limits a single implementation to 12 chassis (96 servers) for support and this increases with each major release. Let’s take a look at the 8 chassis 64 server implementation for comparison to an equal HP VC domain.

In the diagram above we see an 8 chassis 64 server implementation utilizing the minimum number of links per chassis to provide redundancy (the same as was done in the HP example above. Here we utilize 16 links for 8 chassis providing 20Gbps of LAN and SAN traffic to each chassis. Because there is no blocking required for loop-prevention all links shown are active. Additionally because the Fabric Interconnects shown here in green are the access/edge switches for this topology all east/west traffic between servers in a single chassis or across chassis is fully accounted for. Depending on bandwidth requirements additional uplinks could be added to each chassis. Lastly there would be no additional management cables required from the interconnects to the chassis as all management is handled on dedicated, prioritized internal VLANs.
In the system above all traffic is aggregated upstream via the two fabric interconnects, this means that accounting for North/South traffic is handled by calculating the bandwidth needs of the entire system and designing the appropriate number of links.
Side by Side Comparison:
 In the diagram we see a maximum server scale VC Domain compared to an 8 chassis UCS domain. The diagram shows both domains connected up to a shared two-tier SAN design (core/edge) and 3 tier network design (Access, Aggregation, Core.) In the UCS domain all access layer connectivity is handled within the system.
In the diagram we see a maximum server scale VC Domain compared to an 8 chassis UCS domain. The diagram shows both domains connected up to a shared two-tier SAN design (core/edge) and 3 tier network design (Access, Aggregation, Core.) In the UCS domain all access layer connectivity is handled within the system.
In the next diagram we look at an alternative connectivity method for the HP VC domain utilizing the switch modules in the HP chassis as the access layer to reduce infrastructure.

In this method we have reduced the switching infrastructure by utilizing the onboard switching of the HP chassis as the access layer. The issue here will be the bandwidth requirements and port costs at the LAN aggregation/SAN core. Depending on application bandwidth requirements additional aggregation/core ports will be required which can be more costly/complex than access connectivity. Additionally this will increase cabling length requirements in order to tie back to the data center aggregation/core layer.Â
Summary:
When comparing UCS to HP blade implementations a base UCS blade implementation is best compared against a single VC domain in order to obtain comparable feature parity. The total port and bandwidth counts from the chassis for a minimum redundant system are:
| Â |
HP |
Cisco |
| Total uplinks |
13 |
16 |
| Gbps FC |
16 per chassis |
N/A |
| Gbps Ethernet |
10 per VLAN per VC Domain/ 20 Total |
N/A |
| Consolidated I/O |
N/A |
20 per chassis |
| Total Chassis I/O |
21 Gbps for 16 servers |
20 Gbps for 8 servers |
Â
This does not take into account the additional management ports required for the VC domain that will not be required by the UCS implementation. An additional consideration will be scaling beyond 64 servers. With this minimal consideration the Cisco UCS will scale to 40 chassis 320 servers where the HP system scales in blocks of 4 chassis as independent VC domains. While multiple VC domains can be managed by a Virtual Connect Enterprise Manager (VCEM) server the network stacking is done per 4 chassis domain requiring North/South traffic for domain to domain communication.
The other networking consideration in this comparison is that in the default mode all links shown for the UCS implementation will be active. The HP implementation will have one available uplink or port aggregate uplink per VLAN for each VC domain, further restraining bandwidth and/or requiring additional ports.